摘要
在當今數字化轉型步伐不斷加快的時代,IT應用系統的穩定運行成爲了企業的業務正常運轉的重要基礎,因此,運維管理體(tǐ)系的構建也從圍繞着數據中(zhōng)心轉向圍繞着應用系統方向,首個專門面向應用運維的理論體(tǐ)系——SRE,由Google發布後,受到了越來越多的企業的青睐,很多國内企業已經紛紛效仿Google建立SRE團隊,旨在爲各個業務應用系統提供更好的穩定性保障能力,爲業務保駕護航。
企業轉型與快速發展帶來的業務異構化必然導緻了IT環境的多樣化異構化,在不同業務架構和應用架構下(xià),IT踐行SRE理念、建設一(yī)個先進的穩定性平台也必然是一(yī)個循序漸進的過程,本文主要參考SRE中(zhōng)的部分(fēn)核心理論,從運維标準化和技術工(gōng)具層面闡述如何建設穩定性能力。
關于SRE和穩定性
SRE的理論很多人都已經比較熟悉,最早是Google的一(yī)本書(shū)《Site Reliability Engineering: How Google Runs Production Systems》分(fēn)享了他們如何構建、部署和運維監控他們龐大(dà)的軟件系統。
SRE提出的目标:
隻要是軟件,就可能存在bug或者各種運行上的問題。而SRE就是聚焦于的軟件系統的穩定性運行。
SRE提出的管理體(tǐ)系:
SRE提出了要有服務質量目标(SLO)、on-call輪值、變更和事故管理、故障複盤、應急響應機制等一(yī)系列的管理手段。
SRE提出的組織體(tǐ)系:
SRE強調以軟件工(gōng)程的方式來解決這些穩定性問題,SRE團隊中(zhōng)所有的人都具有軟件開(kāi)發能力,其中(zhōng)50% ~ 60%是純軟件工(gōng)程師,40% ~ 50%既具備軟件開(kāi)發技能,又(yòu)具備運維技術(PS:如果運維能有這樣的人員(yuán)配比,感覺“永不宕機”指日可待)。
SRE提出的技術體(tǐ)系:
人員(yuán)能力目标太難達到,我(wǒ)們還是從“事”的角度出發吧。Google認爲SRE的職責在于負責軟件系統的可用性、時延、性能、效率、變更管理、監控、應急響應和容量管理相關的工(gōng)作。
前面提到,在企業IT環境異構化的情況下(xià),穩定性能力建設絕不是一(yī)個簡單的話(huà)題,它需要标準化、流程化、數據化,需要将ITOM的配置、監控、自動化、流程等能力融合,需要我(wǒ)們結合多年的運維經驗和不斷湧現的各種運維技術來逐步構建、升華。
穩定性能力建設的基礎
首先,标準化先行。
運維界現在在大(dà)談AIOps,但我(wǒ)們知(zhī)道,除了關鍵的AI算法能力外(wài),有質量的數據也是AI的基礎。對于運維來說也是如此,高質量的運維數據是AIOps落地的基礎,高質量的運維數據不會憑空出現,需要IT标準化。同樣,穩定性的踐行,要求我(wǒ)們實現一(yī)定程度的标準化。
對于大(dà)部分(fēn)企業來說,由于處于數字化轉型高速發展的階段,并且由于曆史的原因,業務應用架構短期内很難以實現标準化,異構化一(yī)定是一(yī)種常态,那運維在标準化訴求面前是否就束手無策了呢,其實未必,我(wǒ)們仍然可以找到另一(yī)條标準化的道路,就是把我(wǒ)們的運維基礎能力抽象、标準化,來适配各種不同的業務架構。
01 CMDB标準化
CMDB标準化有以下(xià)兩個基本原則:
以應用爲中(zhōng)心建設CMDB,并且标準應用部署拓撲模型,如業務-環境-子系統-集群-模塊(參考下(xià)圖),讓其能支撐傳統、分(fēn)布式、雲原生(shēng)等各種應用架構。
從配置消費(fèi)(發布、監控、自動化等)角度出發,在CMDB中(zhōng)标準化應用系統及其相關資(zī)源的模型信息,如應用進程、API、網站、應用調用關系,應用關聯的數據庫,容器工(gōng)作負載、容器集群和命名空間配置模型等等(參考下(xià)圖)
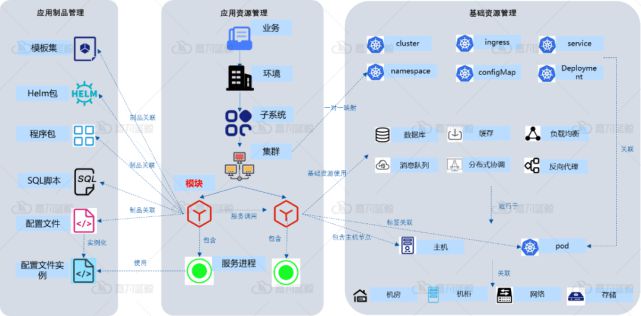
除了上述兩點之外(wài),在運維新時代,要做好一(yī)個CMDB,不僅僅是工(gōng)具,還需要配套的标準規範、組織、流程,這裏不進行一(yī)一(yī)贅述,有興趣的同學可以翻閱過往的文章:
【深度好文】以應用爲中(zhōng)心的CMDB究竟應該如何設計?
【深度好文】回歸本質,重新認識CMDB ——CMDB項目建設思考
02 監控标準化
在以業務系統穩定性爲目标的前提下(xià),我(wǒ)們對監控提出了新的要求:
監控對象标準化
監控系統需要與以應用爲中(zhōng)心的CMDB打通,監控系統中(zhōng)的監控對象來自于CMDB中(zhōng)标準化管理的應用資(zī)源對象,從而具備以應用視角的監控展現和分(fēn)析能力。
監控指标标準化
每個應用系統所提供的業務功能各不相同,應用系統的架構和資(zī)源組成也多種多樣,但我(wǒ)們仍可以需要從各個層次、各個維度來抽象出一(yī)套相對通用的應用系統可觀測性指标(見下(xià)圖)。
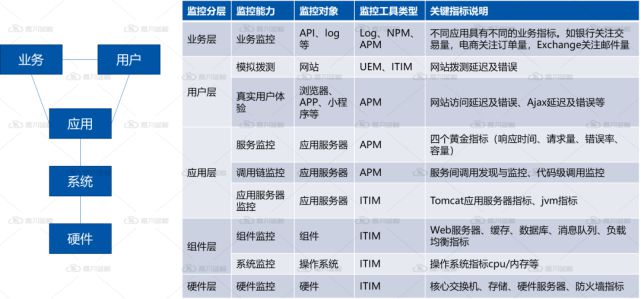
03 能力标準化
經過抽象之後,自動化運維的底層能力主要包括以下(xià)幾種:
命令通道能力
提供基于os之上的各種命令執行通道,如shell、bat、perl、sql等等。
文件通道能力
提供快速的文件傳輸能力。
數據通道能力
提供标準的數據采集框架支持各種類型數據采集,如日志(zhì)、系統性能、數據庫、腳本和自定義協議采集等。
API通道能力
提供統一(yī)的API Gateway來管理和對接各個業務系統或運維系統的接口。
持續拓展能力
其他自定義協議對接。
04 運維場景标準化
要實現穩定性的目标,還需要不斷積累各種标準化運維場景能力,如故障分(fēn)析場景、故障自愈場景、應急處置場景。
其次,标準化之後,我(wǒ)們還需要考慮流程化,比如CMDB的配置入庫流程,監控告警的處理閉環流程,發布變更流程,故障處理流程、故障複盤及知(zhī)識庫沉澱的流程等等。
最後,數據化則是穩定性踐行的關鍵基礎,舉個故障分(fēn)析定位的例子,一(yī)個故障可能是配置變更或軟件版本更新導緻,可能是依賴的外(wài)部服務故障導緻,可能是自身的數據庫、進程或代碼運行問題導緻,定位問題的過程,一(yī)定要能夠整合這些配置、流程、監控等數據,才能實現一(yī)定程度的故障分(fēn)析定位自動化。這裏額外(wài)提一(yī)下(xià),在當前企業架構多樣化的情況下(xià),基于AI的告警收斂和關聯,隻是故障分(fēn)析中(zhōng)的一(yī)個能力組成,而不是理想主義者所期望的,基于AI去(qù)分(fēn)析海量告警信息就能直接實現根因定位。
如何建設穩定性平台
基于SRE的理論,應用運維應該打造自己的穩定性保障平台。“穩定性”仍然是一(yī)個比較泛的概念,因此我(wǒ)們可以從它的反面——“故障”來切入。
結合ITIL中(zhōng)事故管理和問題管理的理論,應用運維構建故障分(fēn)析和處置平台能力,可以參照以下(xià)故障管理的閉環進行開(kāi)展:
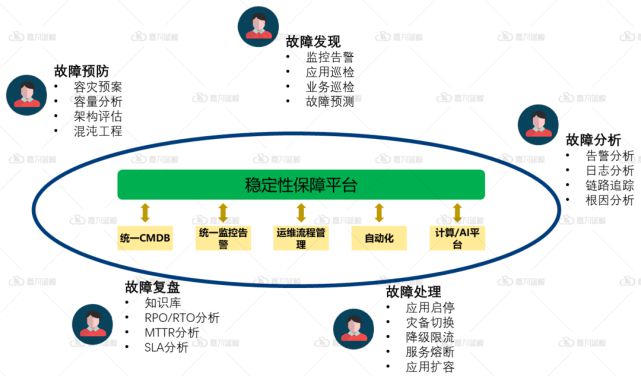
01 故障預防階段
1. 需要基于标準化的CMDB和監控告警系統構建容量分(fēn)析體(tǐ)系,以提前預測發現應用性能瓶頸,避免故障發生(shēng)(見下(xià)圖)
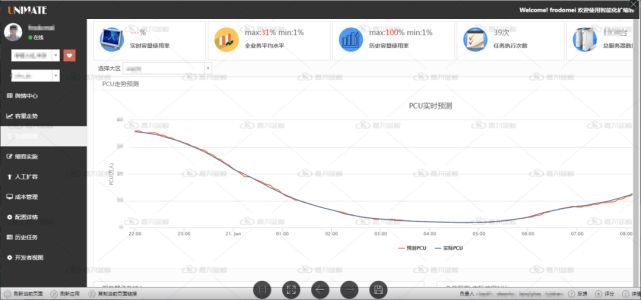
2. 積累标準化的和應用個性化的應急處置自動化預案,以便于應用在發生(shēng)故障時可以快速恢複
3. 根據應用高可用架構标準,自動評估各個應用系統的架構可用性能力
4. 針對關鍵的業務系統,構建混沌工(gōng)程來檢驗業務系統對故障的自動屏蔽和消除能力,并不斷積累通用的混沌工(gōng)具場景
02 故障發現階段
1. 從Metric、Logging、Tracing三種方式實現應用系統的全方位監控和告警
2. 基于自動化的能力實現應用系統組件和業務功能的主動健康檢查

3. 基于單指标異常檢測的算法實現一(yī)定程度的故障預測能力。
03 故障分(fēn)析和定位階段
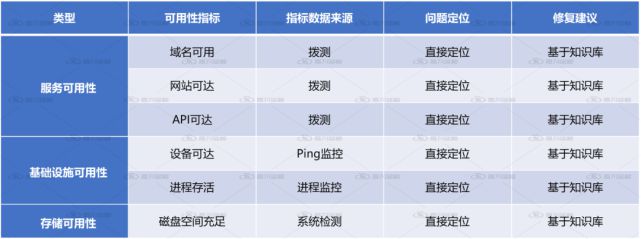
要實現故障的分(fēn)析定位,首先,我(wǒ)們得對應用系統故障源有清晰和全面的了解。根據多個行業及客戶的調研數據,應用系統的故障一(yī)般會有以下(xià)幾種來源:
A、基礎設施可用性問題
包括域名不可達、網絡設備或主機故障、主機磁盤空間爆滿、進程卡死或停止等。
B、基礎設施性能問題
包括數據庫、中(zhōng)間件、消息隊列、負載均衡、操作系統等遇到性能瓶頸等。
C、應用調用鏈問題
由一(yī)個服務引發了另一(yī)個服務的異常。
D、代碼異常問題
業務邏輯設計或代碼隐藏缺陷引發的可用性或性能問題,或由于變更更新引發的應用故障。
在标準化的CMDB、監控和流程等運維體(tǐ)系的基礎上,我(wǒ)們希望故障分(fēn)析和定位系統,能夠結合以上這些運維經驗幫我(wǒ)們排查和定位問題:
從應用視角進行基本可用性分(fēn)析
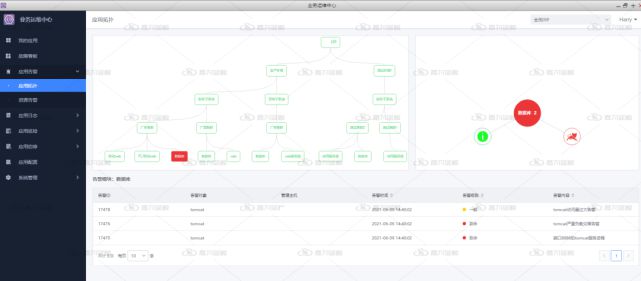
從應用視角進行基礎資(zī)源問題分(fēn)析

基礎資(zī)源問題分(fēn)析展示
從應用視角進行用戶體(tǐ)驗問題分(fēn)析

從應用角度進行應用性能問題分(fēn)析

應用運行日志(zhì)告警展示
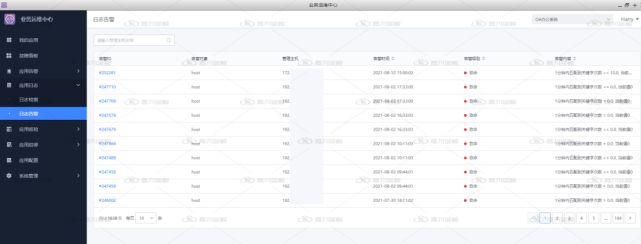
故障影響分(fēn)析能力
基于CMDB中(zhōng)應用調用關系、資(zī)源關聯關系提供故障傳播鏈,展示故障上遊受影響組件和下(xià)遊可能的故障源組件。
容量分(fēn)析能力
根據容量分(fēn)析能力判斷當前資(zī)源容量是否能夠支撐業務訪問量或交易量。
近期變更前後關鍵指标對比分(fēn)析
獲取近期變更數據,展示和對比變更前後應用系統關鍵的可用性和性能指标數據。并結合故障時間點進行關聯分(fēn)析。
故障彙總與定位看闆
彙總展示關鍵指标告警及分(fēn)析結果。
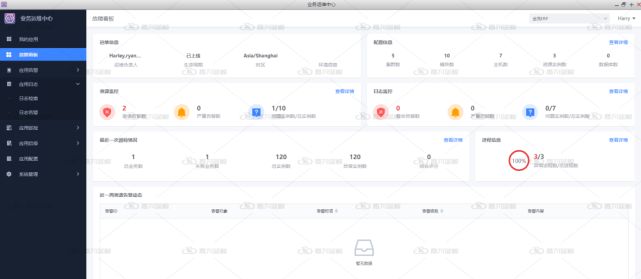
04 故障處理階段
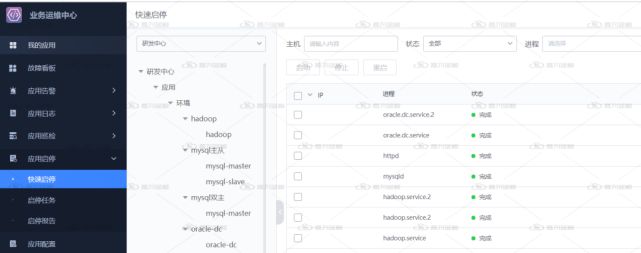
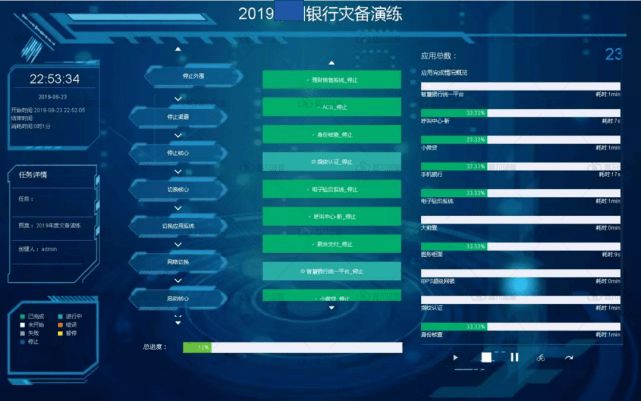
- 根據應用架構特征,提供快速的限流降級、服務熔斷的微服務自動化運維能力
最後,在故障複盤階段,除了分(fēn)析相關的RPO/MTTR/SLA等指标,還需要通過流程等手段沉澱新故障場景到知(zhī)識庫中(zhōng),以不斷提升故障分(fēn)析和處置能力。
通網站建設,南(nán)通網站設計")





































通網站建設")

